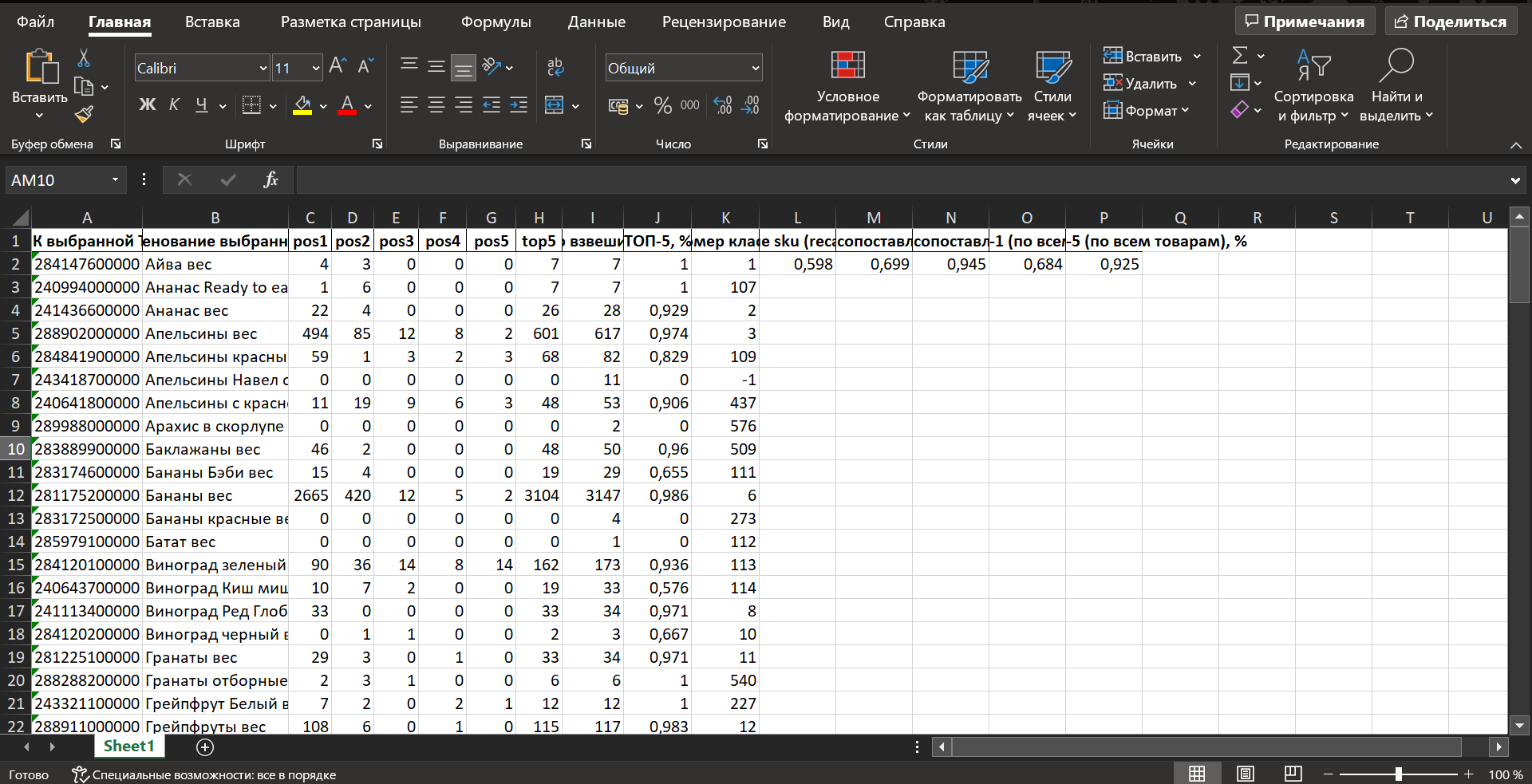
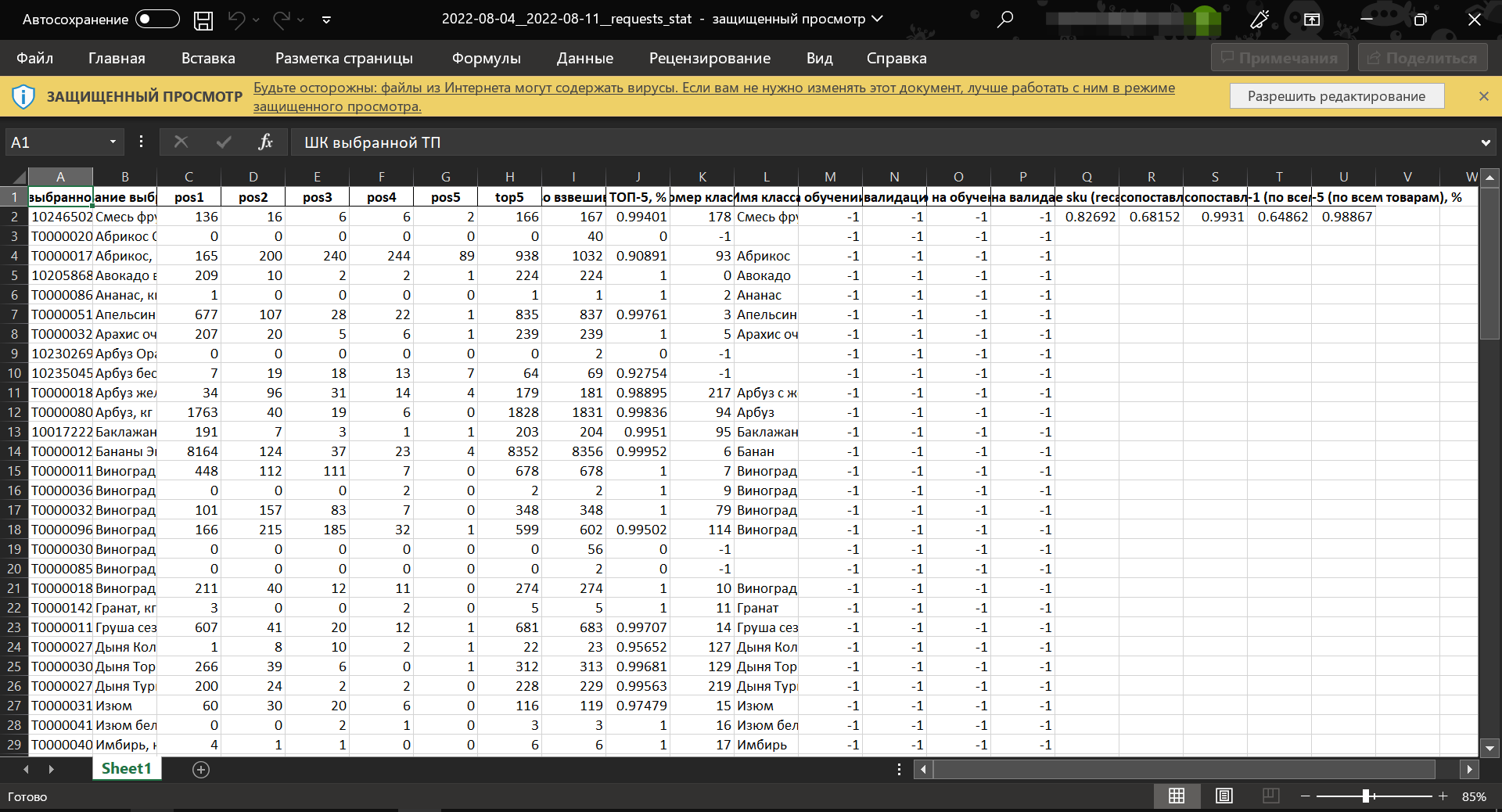
Данный отчет содержит уже обработанные и проанализированные данные об эпизодах распознавания взвешиваний на различных терминалах конечного клиентского устройства, на основании которых система высчитывает процент эффективности своей работы.
...
pos1 – количество эпизодов взвешивания на первом терминале конечного клиентского устройства.
pos2 – количество эпизодов взвешивания на втором терминале конечного клиентского устройства.
pos3 – количество эпизодов взвешивания на третьем терминале конечного клиентского устройства.
pos4 – количество эпизодов взвешивания на четвертом терминале конечного клиентского устройства.
pos5 – количество эпизодов взвешивания на пятом терминале конечного клиентского устройства.
top5 – количество попаданий выбранной пользователем товарной позиции в ТОП-5 рекомендаций системы, предложенных по итогам распознавания товара.
Кол-во взвешиваний – суммарное количество эпизодов распознавания на взвешивания на всех терминалах конечного клиентского устройства. Случаи, когда товарная позиция была выбрана из пик-листа до обращения к СуперМаг Vision, исключаются из данной выборки.
ТОП-5, % – процент попаданий выбранной пользователем товарной позиции в ТОП-5 рекомендаций системы, предложенных по итогам распознавания товара (показатель помогает в определении пересорта).
Номер класса – внутренний идентификатор класса.
Имя класса – наименование класса.
Кол-во фото на обучении (по партнеру) – количество фото на обучении в разрезе каждого партнера.
Кол-во фото на валидации (по партнеру) – количество фото на валидации в разрезе каждого партнера.
Кол-во фото на обучении (общее) – общее количество фото на обучении.
Кол-во фото на валидации (общее) – общее количество фото на валидации.
Покрытие sku (recall>=0.85) – количество SKU, распознанных с точностью 85% и выше, относительно общего количества SKU.
Точность ТОП-1 (по сопоставленным товарам), % – процент появления выбранной пользователем товарной позиции в качестве первой (наиболее вероятной) рекомендации системы по итогам распознавания (только для SKU, попавших в определенный класс). Показатель рассчитывается следующим образом: подсчитывается значение M – суммарное количество взвешиваний товаров (за вычетов техвычетом тех, которые не попали ни в один класс). Затем берется N – суммарное количество попаданий этих товаров в ТОП1 (т.е. количество случаев, когда каждый такой товар появляется первым в выдаче результатов распознавания как самый вероятный). Точность ТОП-1 = МN/NM.
Точность ТОП-5 (по сопоставленным товарам), % – процент появления выбранной пользователем товарной позиции в числе ТОП-5 рекомендаций системы по итогам распознавания (только для SKU, попавших в определенный класс). Показатель рассчитывается следующим образом: подсчитывается значение M – суммарное количество взвешиваний товаров (за вычетов техвычетом тех, которые не попали ни в один класс). Затем берется N – суммарное количество попаданий этих товаров в ТОП5 (т.е. количество случаев, когда каждый такой товар появляется в выдаче пяти результатов распознавания). Точность ТОП-5 = МN/NM.
Точность ТОП-1 (по всем товарам), % – процент появления выбранной пользователем товарной позиции в качестве первой (наиболее вероятной) рекомендации системы по итогам распознавания (для всех SKU). Показатель рассчитывается следующим образом: подсчитывается значение M – суммарное количество взвешиваний всех товаров. Затем берется N – суммарное количество попаданий этих товаров в ТОП1 (т.е. количество случаев, когда каждый такой товар появляется первым в выдаче результатов распознавания как самый вероятный). Точность ТОП-1 = М/N.
Точность ТОП-5 (по всем товарам), % – процент появления выбранной пользователем товарной позиции в числе ТОП-5 рекомендаций системы по итогам распознавания (для всех SKU). Показатель рассчитывается следующим образом: подсчитывается значение M – суммарное количество взвешиваний всех товаров. Затем берется N – суммарное количество попаданий этих товаров в ТОП5 (т.е. количество случаев, когда каждый такой товар появляется в выдаче пяти результатов распознавания). Точность ТОП-5 = МN/NM.
Пользуясь данными этого отчета, можно легко обнаружить товары, процент распознавания которых низок, выявить причины и предпринять соответствующие меры: обучить нейросеть распознаванию определенного товара, либо привязать штрихкод товарной позиции к соответствующему классу нейросети.